
Dobos: “Why write rules for software by hand when AI can just think every pixel for you?”
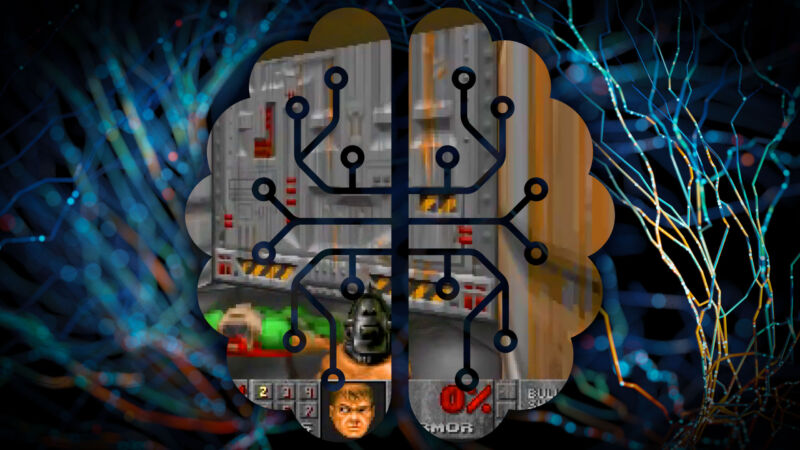
On Tuesday, researchers from Google and Tel Aviv University unveiled GameNGen, a new AI model that can interactively simulate the classic 1993 first-person shooter game Doom in real time using AI image generation techniques borrowed from Stable Diffusion. It’s a neural network system that can function as a limited game engine, potentially opening new possibilities for real-time video game synthesis in the future.
For example, instead of drawing graphical video frames using traditional techniques, future games could potentially use an AI engine to “imagine” or hallucinate graphics in real time as a prediction task.
Google’s Genie game maker is what happens when AI watches 30K hrs of video games
“The potential here is absurd,” wrote app developer Nick Dobos in reaction to the news. “Why write complex rules for software by hand when the AI can just think every pixel for you?”
GameNGen can reportedly generate new frames of Doom gameplay at over 20 frames per second using a single tensor processing unit (TPU), a type of specialized processor similar to a GPU that is optimized for machine learning tasks.
In tests, the researchers say that ten human raters sometimes failed to distinguish between short clips (1.6 seconds and 3.2 seconds) of actual Doom game footage and outputs generated by GameNGen, identifying the true gameplay footage 58 percent or 60 percent of the time.
An example of GameNGen in action, interactively simulating Doom using an image synthesis model.
Real-time video game synthesis using what might be called “neural rendering” is not a completely novel idea. Nvidia CEO Jensen Huang predicted during an interview in March, perhaps somewhat boldly, that most video game graphics could be generated by AI in real time within five to 10 years.
GameNGen also builds on previous work in the field, cited in the GameNGen paper, that includes World Models in 2018, GameGAN in 2020, and Google’s own Genie in March. And a group of university researchers trained an AI model (called “DIAMOND“) to simulate vintage Atari video games using a diffusion model earlier this year.
Also, ongoing research into “world models” or “world simulators,” commonly associated with AI video synthesis models like Runway’s Gen-3 Alpha and OpenAI’s Sora, is leaning toward a similar direction. For example, during the debut of Sora, OpenAI showed demo videos of the AI generator simulating Minecraft.
Ars Video
How Lighting Design In The Callisto Protocol Elevates The Horror
Diffusion is key
In a preprint research paper titled “Diffusion Models Are Real-Time Game Engines,” authors Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter explain how GameNGen works. Their system uses a modified version of Stable Diffusion 1.4, an image synthesis diffusion model released in 2022 that people use to produce AI-generated images.
“Turns out the answer to ‘can it run DOOM?’ is yes for diffusion models,” wrote Stability AI Research Director Tanishq Mathew Abraham, who was not involved with the research project.
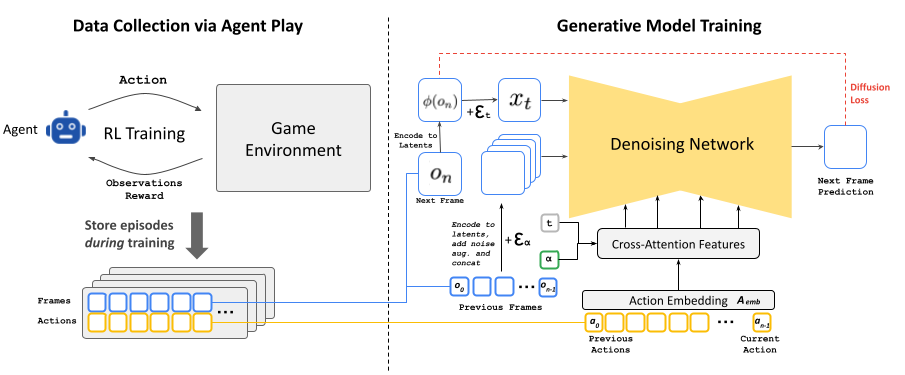
While being directed by player input, the diffusion model predicts the next gaming state from previous ones after having been trained on extensive footage of Doom in action.
The development of GameNGen involved a two-phase training process. Initially, the researchers trained a reinforcement learning agent to play Doom, with its gameplay sessions recorded to create an automatically generated training dataset—that footage we mentioned. They then used that data to train the custom Stable Diffusion model.
However, using Stable Diffusion introduces some graphical glitches, as the researchers note in their abstract: “The pre-trained auto-encoder of Stable Diffusion v1.4, which compresses 8×8 pixel patches into 4 latent channels, results in meaningful artifacts when predicting game frames, which affect small details and particularly the bottom bar HUD.”
An example of GameNGen in action, interactively simulating Doom using an image synthesis model.
And that’s not the only challenge. Keeping the images visually clear and consistent over time (often called “temporal coherency” in the AI video space) can be a challenge. GameNGen researchers say that “interactive world simulation is more than just very fast video generation,” as they write in their paper. “The requirement to condition on a stream of input actions that is only available throughout the generation breaks some assumptions of existing diffusion model architectures,” including repeatedly generating new frames based on previous ones (called “autoregression”), which can lead to instability and a rapid decline in the quality of the generated world over time.
Further Reading
Doom’s creators reminisce about “as close to a perfect game as anything we made”
Visual glitching can appear with continued autoregressive image synthesis because small errors in generated frames can accumulate and compound over time, causing the virtual world to become increasingly glitchy, degraded, or nonsensical as more frames are generated. To address this issue, the researchers intentionally added varying levels of random noise to the training data and taught the model to correct this noise. That helps the model maintain the quality of the generated world over extended durations.
Limitations
It’s important to note that while GameNGen represents a notable step forward in a very new and experimental field, it comes with significant limitations. The biggest among them is that the researchers focused on a single game that already exists. Like other Transformer-based models, Stable Diffusion is best at imitation and creating plausible outputs, not generating true novelty.
Also, GameNGen only has access to three seconds of history, so revisiting a Doom level seen before by the player would involve probabilistic guesses about the previous game state without any knowledge of that history to go on—in other words, confabulating or hallucinating data, much like other generative AI models do when generating outputs.
An example of GameNGen in action, interactively simulating Doom using an image synthesis model.
Scaling the GameNGen approach to more complex environments or different game genres will present new challenges. The computational requirements for running similar models in real time might be prohibitive for widespread adoption in the short term, if the technique was to be widely adopted to render video game graphics in the future (who knows, perhaps future game consoles will have dedicated “neural rendering” chips).
Looking ahead
While the current implementation focuses on simulating Doom, a game with relatively simple graphics by today’s standards, GameNGen suggests that more complex games and simulations could be within reach for future iterations of the technology. As AI models continue to advance (and computation becomes cheaper), we may see increasingly sophisticated neural game engines capable of generating large, consistent interactive worlds in real time. It would also fundamentally change how video games are made.
Further Reading
After watching 50,000 hours of Pac-Man, Nvidia’s AI generated a playable clone
“Today, video games are programmed by humans,” write the researchers in their paper. “GameNGen is a proof-of-concept for one part of a new paradigm where games are weights of a neural model, not lines of code.”
The researchers speculate that with the technique, new video games might be created “via textual descriptions or examples images” rather than programming, and people may be able to convert a set of still images into a new playable level or character for an existing game based solely on examples rather than relying on coding skill.
All that is pure speculation at the moment. For now, we’ll have to wait and see where the research goes and how these new techniques might be applied to interactive gaming in the future.




{kind=link}