
All non-Google chat GPTs affected by side channel that leaks responses sent to users.

AI assistants have been widely available for a little more than a year, and they already have access to our most private thoughts and business secrets. People ask them about becoming pregnant or terminating or preventing pregnancy, consult them when considering a divorce, seek information about drug addiction, or ask for edits in emails containing proprietary trade secrets. The providers of these AI-powered chat services are keenly aware of the sensitivity of these discussions and take active steps—mainly in the form of encrypting them—to prevent potential snoops from reading other people’s interactions.
But now, researchers have devised an attack that deciphers AI assistant responses with surprising accuracy. The technique exploits a side channel present in all of the major AI assistants, with the exception of Google Gemini. It then refines the fairly raw results through large language models specially trained for the task. The result: Someone with a passive adversary-in-the-middle position—meaning an adversary who can monitor the data packets passing between an AI assistant and the user—can infer the specific topic of 55 percent of all captured responses, usually with high word accuracy. The attack can deduce responses with perfect word accuracy 29 percent of the time.
Token privacy
“Currently, anybody can read private chats sent from ChatGPT and other services,” Yisroel Mirsky, head of the Offensive AI Research Lab at Ben-Gurion University in Israel, wrote in an email. “This includes malicious actors on the same Wi-Fi or LAN as a client (e.g., same coffee shop), or even a malicious actor on the Internet—anyone who can observe the traffic. The attack is passive and can happen without OpenAI or their client’s knowledge. OpenAI encrypts their traffic to prevent these kinds of eavesdropping attacks, but our research shows that the way OpenAI is using encryption is flawed, and thus the content of the messages are exposed.”
Mirsky was referring to OpenAI, but with the exception of Google Gemini, all other major chatbots are also affected. As an example, the attack can infer the encrypted ChatGPT response:
- Yes, there are several important legal considerations that couples should be aware of when considering a divorce, …
as:
- Yes, there are several potential legal considerations that someone should be aware of when considering a divorce. …
and the Microsoft Copilot encrypted response:
- Here are some of the latest research findings on effective teaching methods for students with learning disabilities: …
is inferred as:
- Here are some of the latest research findings on cognitive behavior therapy for children with learning disabilities: …
While the underlined words demonstrate that the precise wording isn’t perfect, the meaning of the inferred sentence is highly accurate.
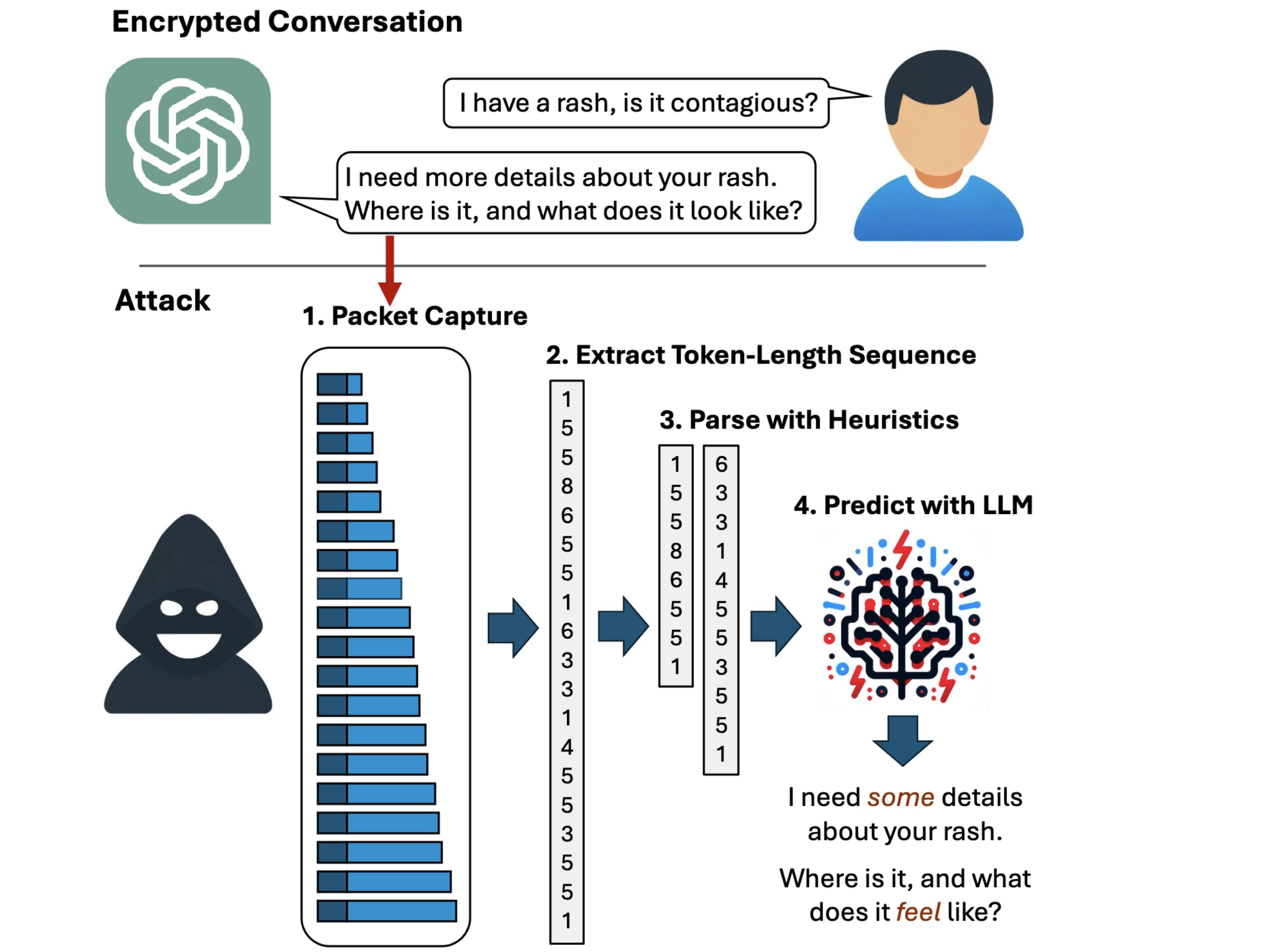
The following video demonstrates the attack in action against Microsoft Copilot:
Token-length sequence side-channel attack on Bing.
A side channel is a means of obtaining secret information from a system through indirect or unintended sources, such as physical manifestations or behavioral characteristics, such as the power consumed, the time required, or the sound, light, or electromagnetic radiation produced during a given operation. By carefully monitoring these sources, attackers can assemble enough information to recover encrypted keystrokes or encryption keys from CPUs, browser cookies from HTTPS traffic, or secrets from smartcards. The side channel used in this latest attack resides in tokens that AI assistants use when responding to a user query.
Tokens are akin to words that are encoded so they can be understood by LLMs. To enhance the user experience, most AI assistants send tokens on the fly, as soon as they’re generated, so that end users receive the responses continuously, word by word, as they’re generated rather than all at once much later, once the assistant has generated the entire answer. While the token delivery is encrypted, the real-time, token-by-token transmission exposes a previously unknown side channel, which the researchers call the “token-length sequence.”
Like Wheel of Fortune for GPTs
First, the attack analyzes the size of each token, which is the same in both encrypted and plaintext form. The length of the token corresponds almost directly to the length of the character string it represents. Next, the attack analyzes the sequence of each token length to arrive at all potential phrases or sentences the words in that order might make up. With millions of potential possibilities for a single sentence and orders of magnitude more for an entire paragraph, the output of this side channel is raw at best.
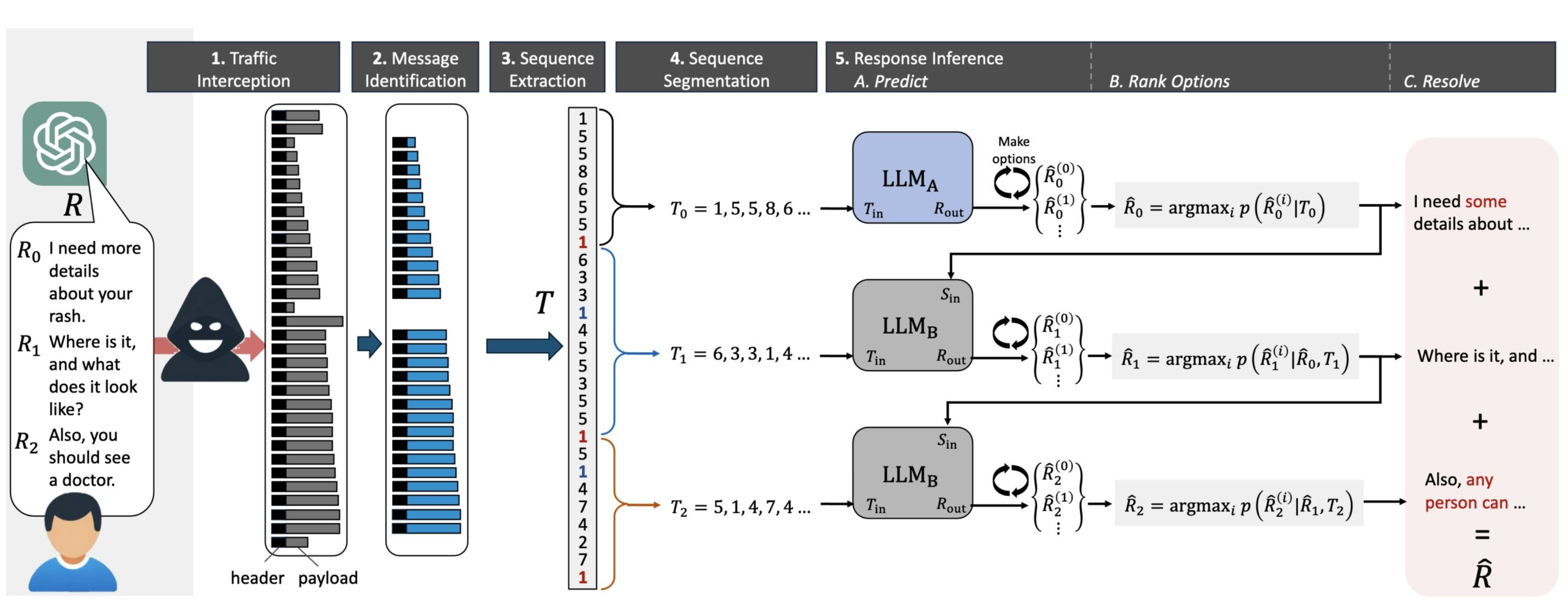
To refine the output, Mirsky and his Ben-Gurion research partners—Roy Weiss, Daniel Ayzenshtyen, and Guy Amit—have devised what they call a token inference attack. It works by running the raw data returned by the side channel through two carefully trained LLMs.
“It’s like trying to solve a puzzle on Wheel of Fortune, but instead of it being a short phrase, it’s a whole paragraph of phrases and none of the characters have been revealed,” Mirsky explained. “However, AI (LLMs) are very good at looking at the long-term patterns and can solve these puzzles with remarkable accuracy given enough examples from other games.”
Since AI assistants talk with a distinct style and repeat certain phrases, it’s possible to identify patterns found in the token-sequence and thus decipher the entire text contextually. This is akin to a known-plaintext attack where an adversary has knowledge of some part of a plaintext and can use it in combination with the corresponding ciphertext to decrypt the entire message.
The researchers found that it’s possible to teach LLMs to perform this attack by training them to translate token-sequences into text using example chats available on the Internet. Since the first sentence in an AI’s response tends to be more stylistic and predictable than those that follow, the researchers refined their results by using one LLM that specializes in deducing the first sentence of a response and another that’s optimized for inferring inner sentences given the context of previous sentences.Advertisement
In a paper published Wednesday, the researchers explained:
LLMs generate and send responses as a series of tokens (akin to words), with each token transmitted from the server to the user as it is generated. While this process is encrypted, the sequential token transmission exposes a new side-channel: the token-length side-channel. Despite encryption, the size of the packets can reveal the length of the tokens, potentially allowing attackers on the network to infer sensitive and confidential information shared in private AI assistant conversations. The challenge for attackers in exploiting the token-length side-channel lies in the inherent complexity of accurately inferring text from a sequence of token-lengths. This difficulty is primarily due to the fact that the tokens from a single sentence can correspond to a multitude of grammatically correct sentences. Moreover, this task becomes exponentially more challenging when the goal is to decipher entire paragraphs, vastly increasing the potential combinations and interpretations.
Previous studies on remote keyloggers have leveraged additional side-channels, such as keystroke timings, to reduce entropy and facilitate the inference of typed information. However, such approaches are not applicable in our setting because LLMs generate tokens for whole words at a time and do not leak character-level information. This presents a unique challenge to traditional side-channel analysis…
To overcome this challenge, we propose a token inference attack that is extremely effective at deciphering responses in encrypted traffic. The approach is to train a state-of-the-art LLM to translate token-length sequences back into legible sentences. Furthermore, by providing the LLM with the context of previously inferred sentences, the LLM can narrow down the possible sentences further, thereby reducing the entropy involved in inferring entire paragraphs. Finally, we show how an adversary can exploit the predictable response style and phrase repetition of LLMs like ChatGPT to refine the model’s accuracy even further. This is achieved by training the attack model with sample chats from the target AI assistant, effectively creating a known-plaintext attack scenario that enhances the model’s ability to infer the sequence of tokens. These sample chats can be readily obtained from public repositories or by accessing the AI assistant service directly as a paying user.
Our investigation into the network traffic of several prominent AI assistant services uncovered this vulnerability across multiple platforms, including Microsoft Bing AI (Copilot) and OpenAI’s ChatGPT-4. We conducted a thorough evaluation of our inference attack on GPT-4 and validated the attack by successfully deciphering responses from four different services from OpenAI and Microsoft.
Anatomy of an AI chatbot
In natural language processing, tokens are the smallest unit of text that carries meaning, although they can also incorporate forms of punctuation and spaces. Consider the sentences “Oh no! I’m sorry to hear that. Try applying some cream.” When tokenized by GTP 3.5 or 4, the sentences are represented as:Advertisement
Oh no! I'm sorry to hear that. Try applying some cream.
LLAMA-1 and LLAMA 2 tokenize them as:
Oh no! I'm sorry to hear that. Try applying some cream.
Every major LLM follows a similar pattern, all of which are designed to break text into manageable units. Major AI assistants make the tokenizer rules public as part of the APIs they provide. Tokens are used not just in the execution of LLMs but also in their training. During training, the LLMs are exposed to vast amounts of data comprising tokenized text, in part so they learn the probability of a particular token following a given sequence. This training allows the LLM to predict the next token in an ongoing conversation accurately.
Conversations comprise two basic message categories: inputs from the user, referred to as prompts, and responses, which are generated by the LLM in response to the inputs. LLMs track the dialog history so that responses incorporate the context contained in preceding inputs and responses. In their paper, the researchers explain:
Prompt (P): A prompt is the user’s input, typically a question or statement, initiating interaction with the LLM. It is represented as a token sequence P = [p1, p2,…, pm] for pi ∈ K.
Response (R): In reply to the prompt, the LLM generates a response, also a sequence of tokens, denoted as R = [r1,r2,…,rn] for ri ∈ K
Not ready for real time
With the exception of Google Gemini, all widely available chat-based LLMs transmit tokens immediately after generating them, in large part because the models are slow and the providers don’t want users to wait until the entire message has been generated before sending any text. This real-time design plays a key role in creating the side channel. Because a token is sent individually, one at a time, adversaries with a passive AitM capability can measure their lengths regardless of encryption. When tokens are sent in large batches, it’s not possible to measure the length of each individual token.
As an example, when the AI assistant sends the text “You should see a doctor” as individual tokens, it transmits a separate packet for each of those words. The payload size of each of those packets will be 3, 6, 3, 1, 6 (plus some static overhead that can be filtered out). Even though an attacker has no idea what characters are in the message, the attacker knows the length of each word and the order of those words in a sentence. This example is a simplification, since, as noted earlier, tokens are not always strictly words.
By contrast, when an AI assistant sends all tokens together, the attacker sees only one packet with a payload size of 19. The attacker in that case won’t know if the packet comprises a single 19-character word or multiple words with a total of 19 letters. This same principle explains why the attack isn’t able to read prompts users send to the chatbots. The tokens in prompts aren’t sent piecemeal; they’re sent in large batches each time a user presses Enter.Advertisement
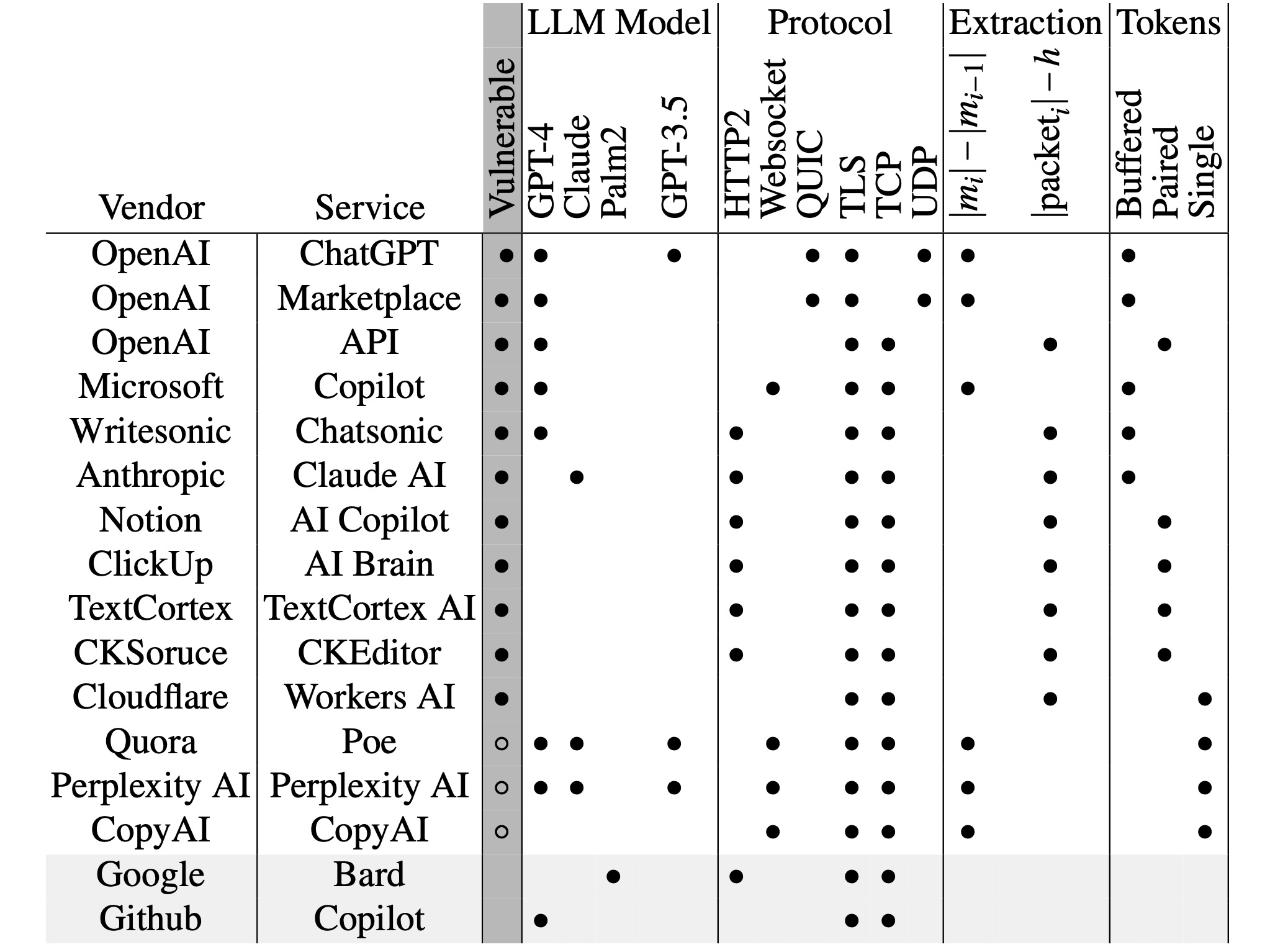
The following table, denoted as Table 1 in the paper, breaks down chatbots from various AI providers to show which ones were, or remain, vulnerable to the attack:
As the researchers explained:
In a real-time communication setting, AI services transmit the next token ri immediately after it is generated. Our observations of several AI assistant services (referenced in Table 1) indicate that the token ri is sent either as an individual message or as part of a cumulative message (e.g., [r1,r2,…,ri]). Crucially, in both scenarios, the packet’s payload length is directly correlated to the number of characters in ri. In the case of cumulative messages, the length of each token can be inferred by calculating the difference in payload length between successive packets. Consequently, for each response message, it is possible to discern the lengths of every single token, even when the traffic is encrypted.
Let the token-length sequence for a response be denoted as T = [t1,t2,…,tn], where ti represents the length of the token ri. The relationship between the token ri and its length ti can be expressed as ti = ∣ri∣, the absolute number of characters in ri. This token-length sequence L can be exploited to infer the original tokens, thereby breaching the privacy of the conversation by revealing every AI response. These responses can also be used to deduce the prompts themselves, either indirectly through context or directly in cases where the AI repeats the question before proceeding.
The diagram below illustrates how the token-length sequence forms the side channel being exploited in this attack:
A complete breach of confidentiality

An attack with only 29 percent perfect accuracy and 55 percent high accuracy may appear to limit its real-world value, but it doesn’t. Using a strict, exact-word accuracy approach such as ROUGE, it’s easy to minimize the practicality of the attack. By passing the predicted and actual texts through a sentence transformer model and then by measuring the *cosine similarly* between that model’s embeddings is more telling. Even if the model botches the exact words, the result can still completely breach the confidentiality of the session.
For example, “Deciding about abortion is a difficult process” and “Thinking about abortion is an important obligation” would fail a Rouge test. Using the cosine similarity approach is much more useful. Using a neural network, the researchers compute the similarity of the actual and guess responses. The rating is represented as Φ (the symbol for phi), with a range from -1.0 to +1.0, where -1.0 means very different and +1.0 means identical. The researchers count any case achieving a phi of greater than 0.5 as a successful attack.
“We found that this attack is extremely good at deciphering responses to common questions people ask their assistants (e.g., history, advice) but struggles on deciphering arbitrary content (e.g., solving a puzzle),” Mirsky wrote in an online interview.
Another seeming limitation is the challenge of training an LLM to accurately guess which words go where in a stream of captured sequences of token lengths.Advertisement
“In the paper, we show how one model (trained e.g., on ChatGPT) works on other services as well,” Mirsky wrote. “This means that once a tool has been built, it could be shared (like other hacking tools) and used across the board with no additional effort.”
An additional challenge is establishing the means to observe packets the chatbot sends to an end user. This capability is relatively straightforward when both the target and adversary are on the same network but is much harder when they’re not, unless the attacker is a nation state or has fine-grained access inside an ISP. In any event, a key reason for the token encryption being broken by this attack is to protect against these scenarios.
The researchers have made two proposals to mitigate the effectiveness of their attack. The first is to follow Google’s example and stop sending packets one at a time. The other is to apply “padding,” a technique that adds random amounts of spaces to packets so that they all have a fixed length equal to the largest possible packet.
Both approaches come with the potential to degrade the chatbot user experience. Sending tokens in large batches can create delays and make the stream choppy. Padding packets will increase the amount of traffic sent in each response.
Of all the chatbots that were vulnerable to the attack, those from OpenAI and Cloudflare have implemented padding mitigations in the past 48 hours. OpenAI declined to comment for this post other than to confirm the mitigation. Cloudflare has published this post, which details the fixes. Microsoft issued a statement that noted the AitM requirement. It added: “Specific details like names are unlikely to be predicted. We are committed to helping protect our customers against these potential attacks and will address it with an update.”
In the coming years, the number of available chat-based LLMs is likely to mushroom. This research should be required reading for anyone involved in their rollout.


