
New model can respond to natural language commands, even on games it has never seen.

At this point in the progression of machine-learning AI, we’re accustomed to specially trained agents that can utterly dominate everything from Atari games to complex board games like Go. But what if an AI agent could be trained not just to play a specific game but also to interact with any generic 3D environment? And what if that AI was focused not only on brute-force winning but instead on responding to natural language commands in that gaming environment?
Those are the kinds of questions animating Google’s DeepMind research group in creating SIMA, a “Scalable, Instructable, Multiworld Agent” that “isn’t trained to win, it’s trained to do what it’s told,” as research engineer Tim Harley put it in a presentation attended by Ars Technica. “And not just in one game, but… across a variety of different games all at once.”
Harley stresses that SIMA is still “very much a research project,” and the results achieved in the project’s initial tech report show there’s a long way to go before SIMA starts to approach human-level listening capabilities. Still, Harley said he hopes that SIMA can eventually provide the basis for AI agents that players can instruct and talk to in cooperative gameplay situations—think less “superhuman opponent” and more “believable partner.”
“This work isn’t about achieving high game scores,” as Google puts it in a blog post announcing its research. “Learning to play even one video game is a technical feat for an AI system, but learning to follow instructions in a variety of game settings could unlock more helpful AI agents for any environment.”
Learning how to learn
Google trained SIMA on nine very different open-world games in an attempt to create a generalizable AI agent.Advertisement
SIMA was trained and tested on the following games provided by Google’s development partners:
- Eco
- Goat Simulator 3
- Hydroneer
- No Man’s Sky
- Satisfactory
- Space Engineers
- Teardown
- Valheim
- Wobbly Life
To train SIMA, the DeepMind team focused on three-dimensional games and test environments controlled either from a first-person perspective or an over-the-shoulder third-person perspective. The nine games in its test suite, which were provided by Google’s developer partners, all prioritize “open-ended interactions” and eschew “extreme violence” while providing a wide range of different environments and interactions, from “outer space exploration” to “wacky goat mayhem.”
Google’s Genie game maker is what happens when AI watches 30K hrs of video games
In an effort to make SIMA as generalizable as possible, the agent isn’t given any privileged access to a game’s internal data or control APIs. The system takes nothing but on-screen pixels as its input and provides nothing but keyboard and mouse controls as its output, mimicking “the [model] humans have been using [to play video games] for 50 years,” as the researchers put it. The team also designed the agent to work with games running in real time (i.e., at 30 frames per second) rather than slowing down the simulation for extra processing time like some other interactive machine-learning projects.
Animated samples of SIMA responding to basic commands across very different gaming environments.
While these restrictions increase the difficulty of SIMA’s tasks, they also mean the agent can be integrated into a new game or environment “off the shelf” with minimal setup and without any specific training regarding the “ground truth” of a game world. It also makes it relatively easy to test whether things SIMA has learned from training on previous games can “transfer” over to previously unseen games, which could be a key step to getting at artificial general intelligence.
For training data, SIMA uses video of human gameplay (and associated time-coded inputs) on the provided games, annotated with natural language descriptions of what’s happening in the footage. These clips are focused on “instructions that can be completed in less than approximately 10 seconds” to avoid the complexity that can develop with “the breadth of possible instructions over long timescales,” as the researchers put it in their tech report. Integration with pre-trained models like SPARC and Phenaki also helps the SIMA model avoid having to learn how to interpret language and visual data from scratch.
ARS VIDEO
How The Callisto Protocol’s Gameplay Was Perfected Months Before Release
Are you good at following directions?
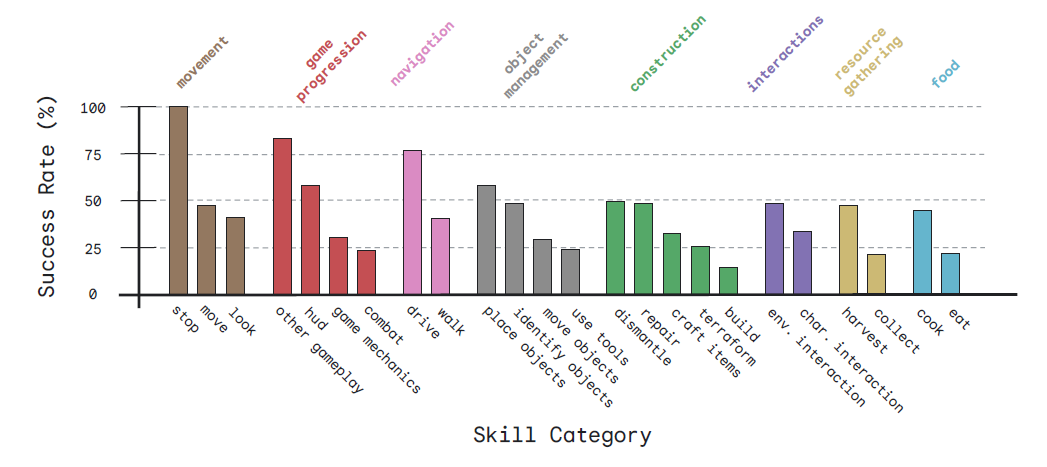
To test SIMA’s learning abilities, DeepMind researchers trained and tested it on nearly 1,500 unique natural language tasks across nine skill categories ranging from movement (e.g., “go ahead”) and navigation (e.g., “go to your ship”) to resource gathering (e.g., “get raspberries”) and object management (e.g., “cut the potato”). The model’s performance on these tasks was then graded mainly by a mixture of “ground-truth” evaluations (e.g., looking at the computer memory to see if a basic task has been completed) and human assessments (e.g., have a person watch gameplay video and judge whether SIMA succeeded).
By comparing training videos across different games and environments, SIMA is able to notice some similarities between instructions across different environments—”go ahead” probably means “press the W key” in most games, to cite a trivial example. The model also shows some ability to combine concepts around basic verbs and nouns—if it learns how to generally “jump on something” in one environment, it can apply that to “jump on car” if it encounters a previously unseen car in a new environment.
In testing, SIMA was often able to complete some basic tasks (e.g., “go to the spaceship”) even when the target object was not in view at the start. More generally, though, the agent’s success varied greatly across different types of commands—the model showed roughly 75 percent success at driving tasks vs 40 percent on walking tasks, for instance.
Notably, a SIMA agent trained on all nine games in the researchers’ set “significantly outperformed specialized agents trained solely on each individual one, showing a greater all-around capability,” as Google’s blog post put it. The tech report quantifies this as a 67 percent improvement when outside games are included in the training data, a sign of “positive transfer” across different environments that serves as a “key milestone” in SIMA’s results, Harley said.Advertisement
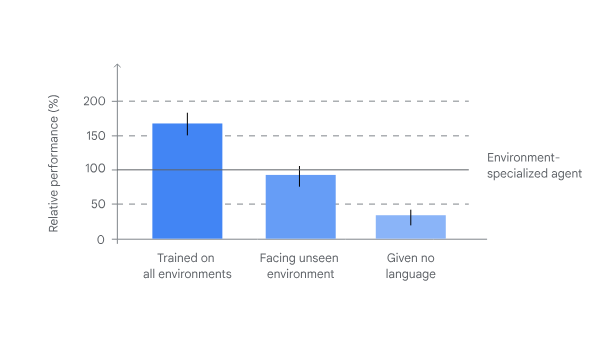
To see how SIMA deals with an environment it has never seen before, DeepMind also created so-called “zero shot” versions of the model, where the agent only receives training on the other games in the training set (and not the game it’s being tested on). The team reports that these models showed “strong performance on general tasks” like navigation and grabbing objects described with a color. But the models still generally fell short on “environment-specific skills,” and performed slightly worse than a model trained specifically on the game being tested.
A starting point
Even with its full nine-game training set, there’s a long way to go before an agent like SIMA can mimic a human’s ability to follow in-game instructions. In No Man’s Sky, for instance, the model only succeeded in 34 percent of tested tasks, compared to 60 percent for a human (the low human score is a reflection of “the difficulty of the tasks we considered in this project and the stringency of our evaluation criteria,” the researchers write).
Speaking to Ars, the researchers said that most of SIMA’s failures relate to “fine-grained understanding” of the environment. While SIMA might do fine with a command like “chop down a tree,” for instance, getting it to understand how to target a specific tree a user might describe is “something we’re actively working on.”
With more training on a wider range of simulated environments, the SIMA team hopes future versions of the model will become “more generalizable and versatile,” as the Google blog puts it, and able to complete “tasks that require high-level strategic planning and multiple sub-tasks, such as ‘Find resources and build a camp.'”
By relating natural language commands to simulated environments, DeepMind hopes SIMA versions can eventually provide a testbed for “future foundation models” that “ground the abstract capabilities of large language models in embodied environments [i.e., the real world].” As Google’s blog post points out, “while Large Language Models have given rise to powerful systems that can capture knowledge about the world and generate plans, they currently lack the ability to take actions on our behalf.”
In other words: Today, Goat Simulator; tomorrow, the world!



