
One weather site’s sudden struggles, and musings on why change isn’t always good.

Since 2017, in what spare time I have (ha!), I help my colleague Eric Berger host his Houston-area weather forecasting site, Space City Weather. It’s an interesting hosting challenge—on a typical day, SCW does maybe 20,000–30,000 page views to 10,000–15,000 unique visitors, which is a relatively easy load to handle with minimal work. But when severe weather events happen—especially in the summer, when hurricanes lurk in the Gulf of Mexico—the site’s traffic can spike to more than a million page views in 12 hours. That level of traffic requires a bit more prep to handle.
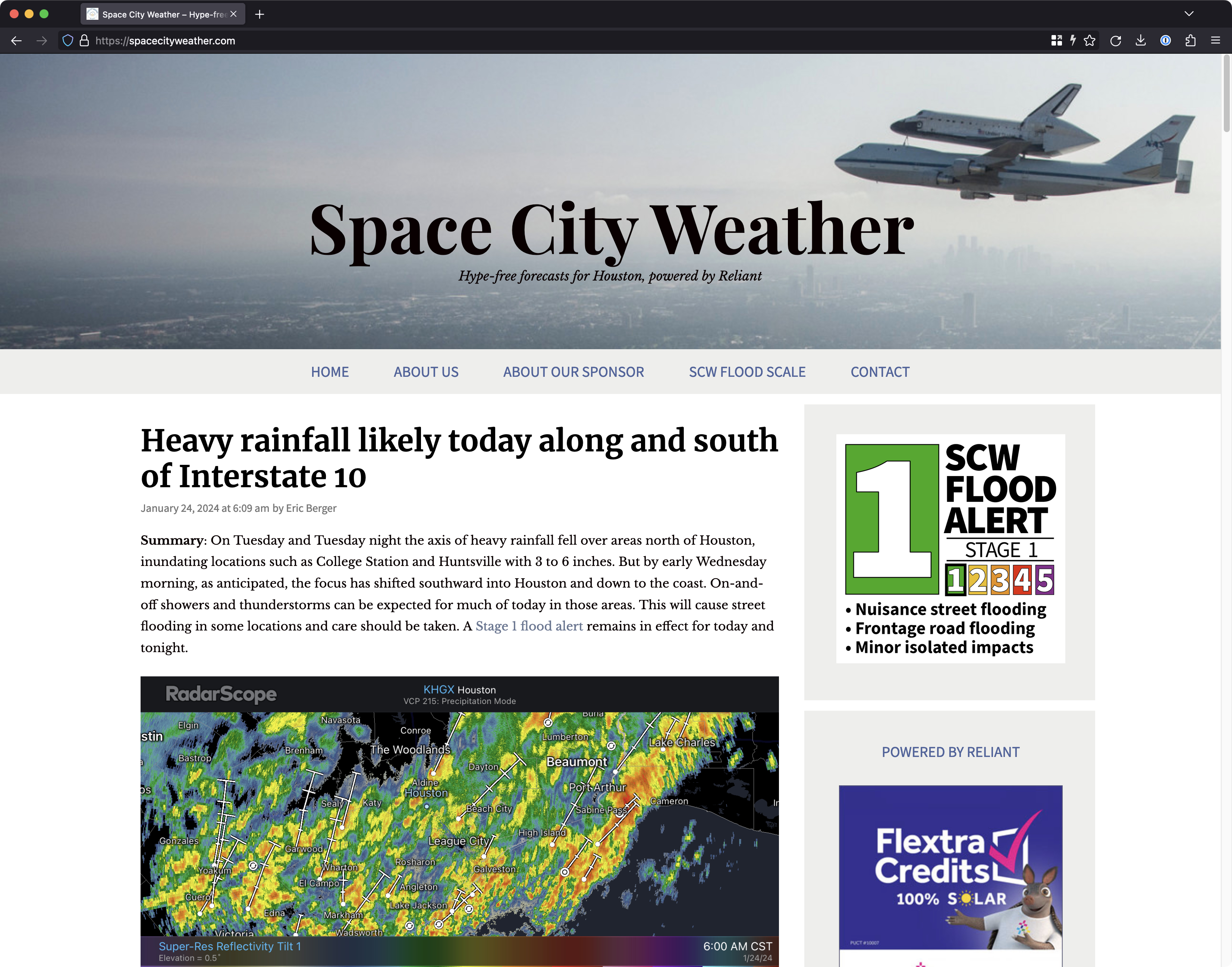
For a very long time, I ran SCW on a backend stack made up of HAProxy for SSL termination, Varnish Cache for on-box caching, and Nginx for the actual web server application—all fronted by Cloudflare to absorb the majority of the load. (I wrote about this setup at length on Ars a few years ago for folks who want some more in-depth details.) This stack was fully battle-tested and ready to devour whatever traffic we threw at it, but it was also annoyingly complex, with multiple cache layers to contend with, and that complexity made troubleshooting issues more difficult than I would have liked.
So during some winter downtime two years ago, I took the opportunity to jettison some complexity and reduce the hosting stack down to a single monolithic web server application: OpenLiteSpeed.
Out with the old, in with the new
I didn’t know too much about OpenLiteSpeed (“OLS” to its friends) other than that it’s mentioned a bunch in discussions about WordPress hosting—and since SCW runs WordPress, I started to get interested. OLS seemed to get a lot of praise for its integrated caching, especially when WordPress was involved; it was purported to be quite quick compared to Nginx; and, frankly, after five-ish years of admining the same stack, I was interested in changing things up. OpenLiteSpeed it was!Advertisement
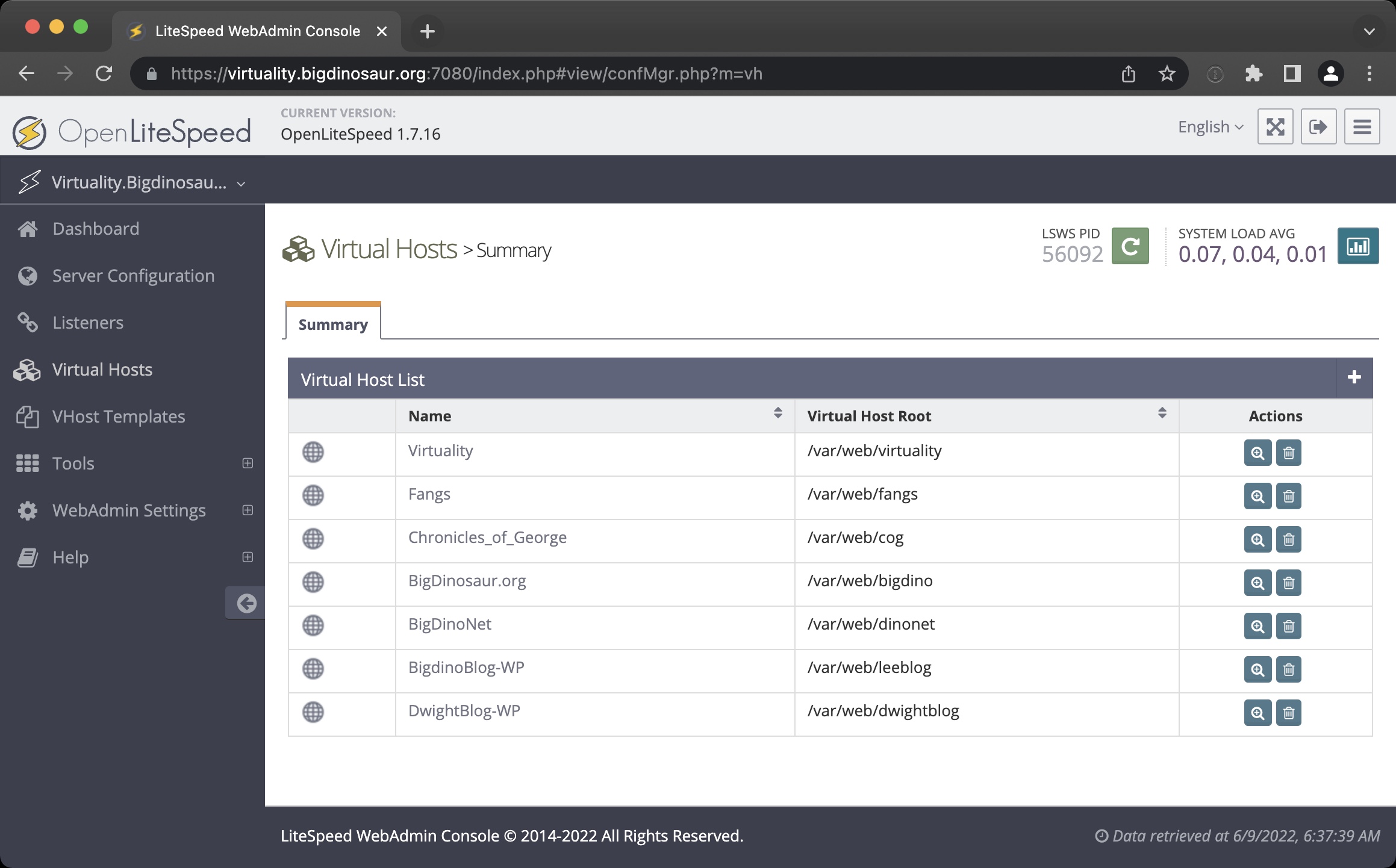
The first significant adjustment to deal with was that OLS is primarily configured through an actual GUI, with all the annoying potential issues that brings with it (another port to secure, another password to manage, another public point of entry into the backend, more PHP resources dedicated just to the admin interface). But the GUI was fast, and it mostly exposed the settings that needed exposing. Translating the existing Nginx WordPress configuration into OLS-speak was a good acclimation exercise, and I eventually settled on Cloudflare tunnels as an acceptable method for keeping the admin console hidden away and notionally secure.
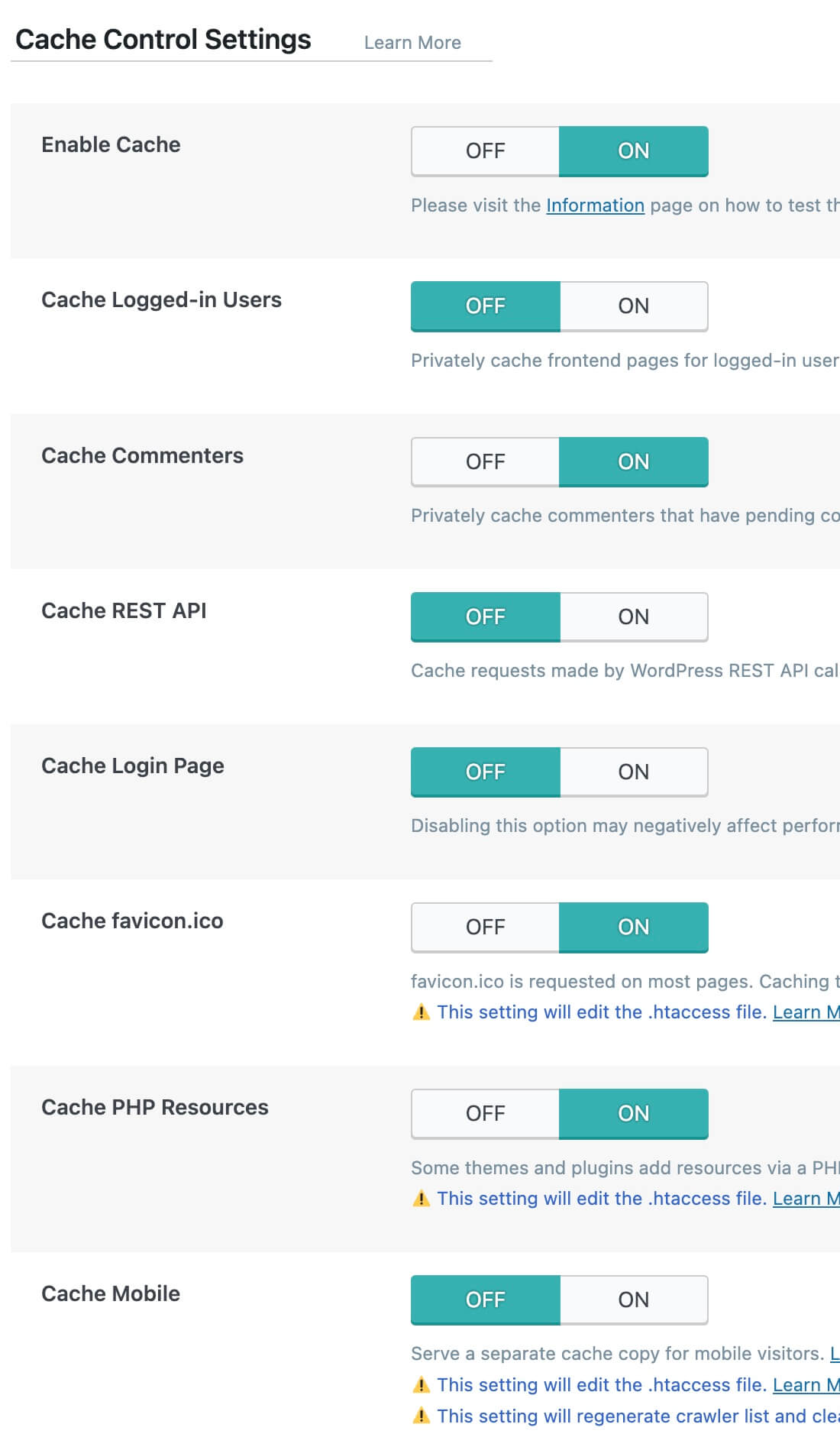
The other major adjustment was the OLS LiteSpeed Cache plugin for WordPress, which is the primary tool one uses to configure how WordPress itself interacts with OLS and its built-in cache. It’s a massive plugin with pages and pages of configurable options, many of which are concerned with driving utilization of the Quic.Cloud CDN service (which is operated by LiteSpeed Technology, the company that created OpenLiteSpeed and its for-pay sibling, LiteSpeed).
Getting the most out of WordPress on OLS meant spending some time in the plugin, figuring out which of the options would help and which would hurt. (Perhaps unsurprisingly, there are plenty of ways in there to get oneself into stupid amounts of trouble by being too aggressive with caching.) Fortunately, Space City Weather provides a great testing ground for web servers, being a nicely active site with a very cache-friendly workload, and so I hammered out a starting configuration with which I was reasonably happy and, while speaking the ancient holy words of ritual, flipped the cutover switch. HAProxy, Varnish, and Nginx went silent, and OLS took up the load.
Teething pains, but not many
Within the first day, it became obvious that one of my primary requirements—the Cloudflare WordPress plugin—wasn’t compatible with the LiteSpeed Cache plugin, At least, not fully and not consistently. This was disappointing because without both plugins, weird stuff happens. (The Cloudflare plugin is required because WordPress needs a way to communicate up to Cloudflare what pages and objects to store in and evict out of Cloudflare’s edge cache; the LiteSpeed Cache plugin does the same for OpenLiteSpeed’s on-box cache. Both plugins need to be in play and operational for your site to work normally for non-logged-in visitors.)
I’ll take a moment here and talk about what in my WordPress administration career has been the biggest recurring nightmare problem to solve: consistent cache invalidation. Whenever Eric Berger makes a new post, or whenever a visitor leaves a comment on an existing post, all the various caching mechanisms that help obviate load on the server need to let go of the currently cached thing they’re holding onto and refresh it with the new thing—the new post by Berger, or the new comment by the visitor, or whatever.
Actually having that cache refresh occur in the right place, with the right things being released from cache and the right new things being grabbed, is shockingly difficult. There’s an entire ludicrous Rube Goldbergian voodoo-esque series of things that happens for WordPress to kick off a cache invalidation, and under the best of circumstances, it only works most of the time. (You know that nixCraft haiku about how problems always turn out to be DNS-related? Here’s the thing—sometimes a problem isn’t caused by DNS. And when a problem isn’t caused by DNS, it’s caused by caching.)Advertisement
And these were not the best circumstances, with the plugins at odds with each other. Still, after poking at the setup in various ways for a week or so (including installing and re-installing the plugins in different orders to see if that helped), the cache situation finally settled into more or less consistent functionality. Posts were being cached and cleared as required; the front page was being cached and cleared as required; the various /feed/ URLs (vital to the functionality of the Space City Weather app, now on the iOS and Google Play stores!) were being flushed and grabbed as pages were refreshed.
Other than getting the plugins to play nice together for cache invalidation, the rollout went smoothly. For almost two years, things were fine. And then, suddenly, they were very much not fine.
The floor drops out
I was pulling my suitcase out of the car’s trunk and negotiating with the valet, and my phone would not stop vibrating. My wife started shuttling our bags toward the hotel’s front door as I spelled my name out for the fellow to write it down on the key tag, and the car’s speakers started blaring my phone’s ringtone.
“Did you leave your phone in the car?” the gentleman helpfully asked as I handed over my keys while the theme to Knight Rider echoed all around us from my car’s open doors.
“No, it’s the Bluetooth,” I said, digging out my phone to reject the call. “ERIC BERGER,” the screen said. It was my wife’s and my 21st wedding anniversary, and we were in the process of checking into a nice hotel for the evening, and Eric was calling. This was not a good sign.
After check-in, rather than grabbing the room service menu, I called Eric back. He told me he’d just posted an update about the cold front approaching the city and that the site had gone non-responsive. He’d tried refreshing and eventually got a “Database connection refused” error—something that had never happened before, even under crushing load. All seemed well now, but for several minutes after posting—during the initial traffic rush on the new post—things had gone sideways.Advertisement
The room service menu sat forlornly, and I pulled out the laptop instead. The backend seemed fine—the server’s CPU load average was hovering around 0.20 or so, and there was plenty of RAM free. The database was fine and accepting connections. The server’s logs showed nothing weird. Cloudflare’s logs showed a handful of origin server errors, but nothing out of the ordinary.
I chalked it up to an isolated event, but unfortunately, it was the start of a trend. The next time Eric posted, I was ready and watching the server, and what I saw was absolutely baffling. As the traffic rush arrived, OLS immediately spawned 200 or so of its lsphp PHP handler processes, and the server’s two CPU cores immediately pegged to 100 percent. The load average shot up to about 15 and sat there. Trying to access anything on the Space City Weather site resulted in either loooooong servicing times (like several seconds) or the request would just time out.
What the hell.
Troubleshooting, such as it was
Over the next two weeks, I tried to attack the problem in every way I knew how. (Fortunately, with Eric posting updates once or twice daily, there were plenty of opportunities to validate the effectiveness of any fixes!) After first auditing the php.ini settings to pull back the number of PHP child processes to a saner level, I thought that maybe Cloudflare had changed how its WordPress APO functionality worked since SCW leans heavily on APO to ensure a high cache hit rate. Perhaps some items that had previously been cached were no longer being cached, leading to higher origin load. This supposition led to a whole bunch of experimentation with Cloudflare page rules and cache rules, increasing the scope of caching.
The idea with this kind of troubleshooting is to find the requests that are making it past Cloudflare and being sent on to your origin server, thereby creating load—and then to see if those requests that are slipping by can instead be cached. Cloudflare has some solid logging tools to help with this, and I found a few edge cases that were making it back to the origin that shouldn’t have been and stopped them.
Unfortunately, while Cloudflare was helpful, I was hampered on the server side by OLS’s inadequate access logging, which stubbornly refused to show details about exactly what requests it was so busy servicing. I don’t know if this was a configuration issue from something I’d done or if the logging is really that awful, but I was profoundly disappointed that the OLS access log didn’t give me useful information and left me flying blind—the LSPHP processes shouldn’t be pegged to the wall while the access and error logs both show absolutely no requests being serviced of any kind. It was one of multiple places where I feel OLS let me down.
(In the application’s defense, I could have spent more time making sure that it was configured to log access to the level I wanted, but I did not spend that time. In fact, it’s probable that this entire article gives OLS short shrift, but my primary goal was to get SCW back to complaint-free operation, and at the time, I wasn’t terribly concerned about doing everything I could to give the product a fair shake. Besides, coming off of something like 19 months of trouble-free hosting on OLS, I felt like I’d already given it that fair shake, and I just wanted the damn website to work properly. If that makes this piece “unfair” to OLS, then so be it.)Advertisement
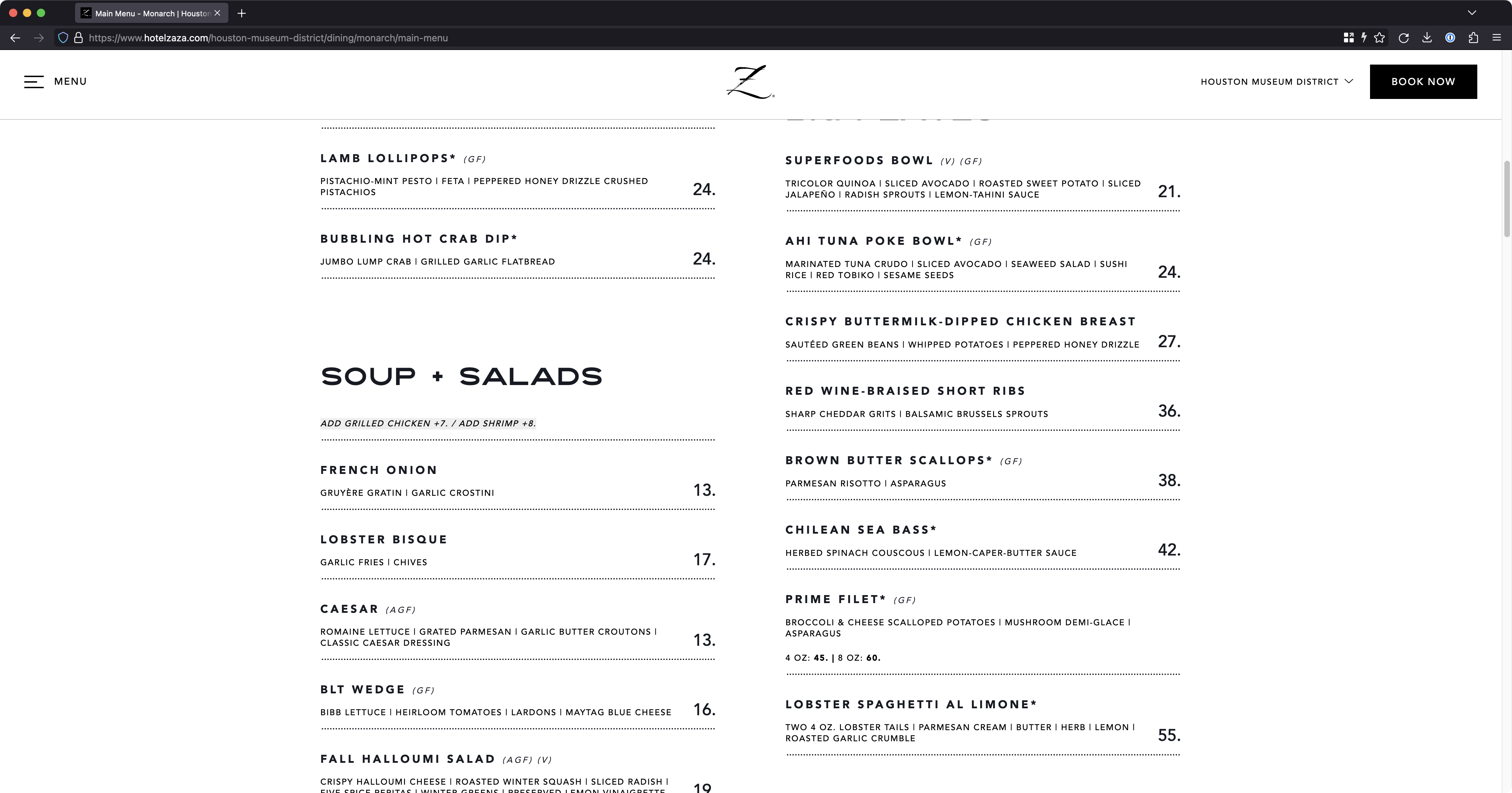
Additionally, there was much troubleshooting hay to be made futzing around with the LiteSpeed Cache WordPress plugin settings to see if I was doing anything wrong there. But after pushing a whole mess of buttons and watching the problem behavior continue more or less unabated, I began to feel that most depressing of troubleshooting feelings creep in—that burning alchemy of defeat, exhaustion, and a powerful desire to blow something up.
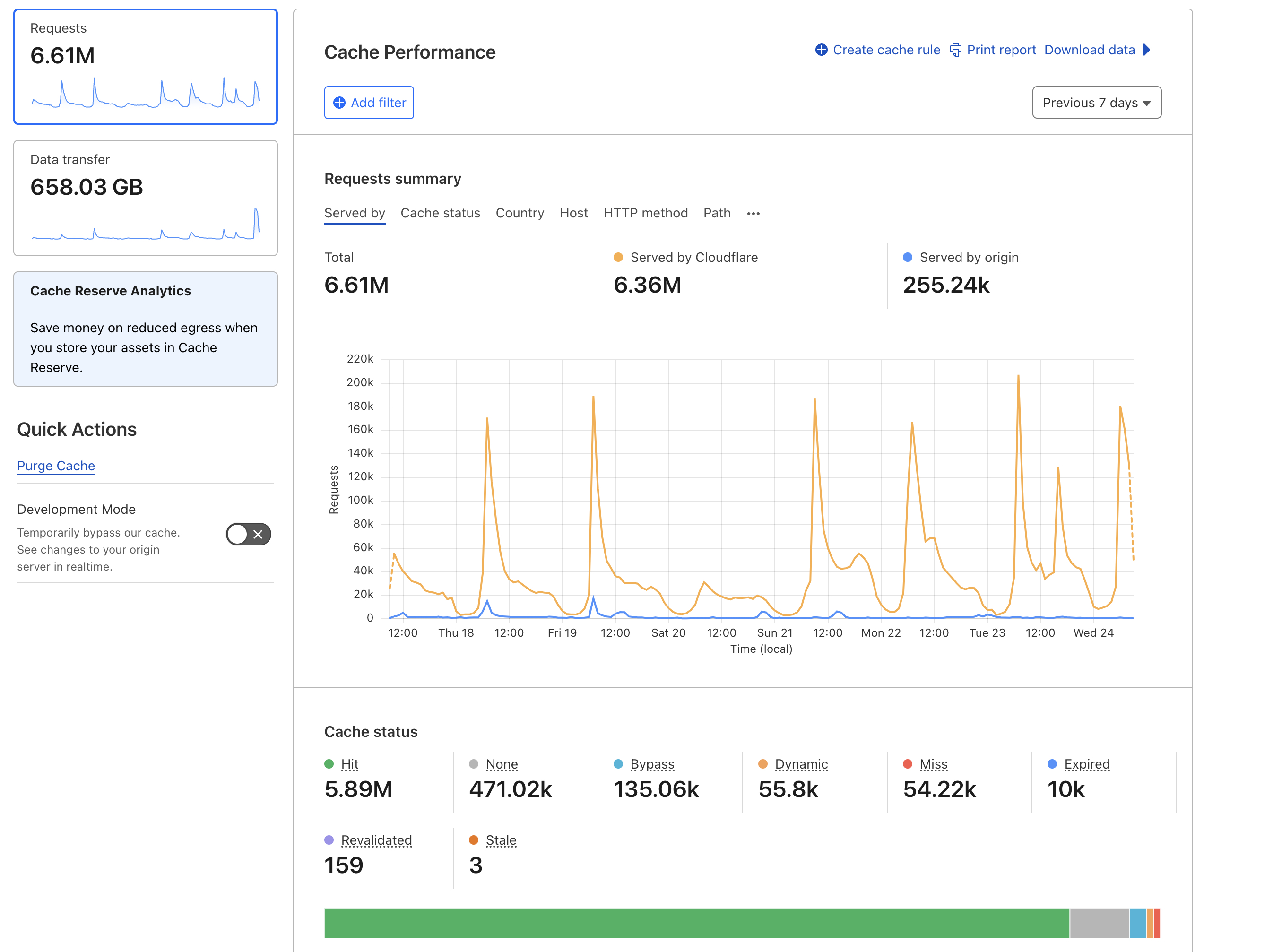
The core issue seemed to simply be load-related. The level of traffic being brought in by the cold weather event was about 10x the usual level of daily traffic, peaking at about 230,000 page views to about 120,000 unique visitors on January 13. While this is a high number, to put it in perspective, it’s still only about 15 percent of the load we’ve gotten during the site’s two major peaks—this level of traffic should be a non-event.
- The total traffic for our January cold weather event. The peak day was January 13, with about 230,000 page views to 120,000 visitors. Lee Hutchinson
- Contrast this to the highest traffic day Space City Weather has ever had, during 2020’s Hurricane Laura, where we did almost 1.6 million PVs to over 500k UVs, and the backend barely registered the load. Lee Hutchinson
Still, even after tweaking the PHP configuration, the server configuration, the WordPress configuration, and the Cloudflare configuration, I kept running into a wall. The visitors would arrive, and the site would go non-responsive. Apparently, this additional load was enough of a deviation from our standard daily traffic to expose the cracks in the configuration, and things would only get worse under the kind of severe traffic that an actual hurricane would bring.
Out with the new, in with the old
That’s how I found myself giving into that desire to blow something up—by ripping out OpenLiteSpeed on a Tuesday afternoon and replacing it with good old Nginx. Because “testing in production” is my middle name, baby.
I think I knew it would always come down to this, from the moment that I got the anniversary trouble call from Eric. Because why, really, did I switch to OLS in the first place? It was flashy and shiny. Managing one application is simpler than managing three. Plus, other folks seemed to really like it! Let’s make a change! Change is fun!
Folks, change isn’t fun. Change is awful. In life, change is often necessary, but when it comes to information systems that are functional and stable, change is the enemy of uptime. Do not embrace change for change’s sake. Only embrace change when you have a set of logical, requirements-driven reasons that are forcing that change upon you. It’s a lesson I thought I knew, and it’s been driven home yet again.
Anyway, things were at least working again—though with the bad weather receding and traffic levels returning to normal, OLS was struggling much less for the last couple of days and might have returned to being viable. But my trust had been too severely damaged—I don’t think I’ll ever switch back to it. (Plus, a GUI? Really? I mean, yeah, you can edit the config files by hand if you really want to, but you’re supposed to use the web interface…)
With the unexpected opportunity to clean-sheet the web server side of things, I’ve focused on simplicity and scale. Gone is the complex HAProxy/Varish/Nginx sandwich—this time around, it’s just plain Nginx. On-box caching is being handled via Nginx’s competent (and easy to admin!) FastCGI cache, which works quite well with WordPress.Advertisement
And it works. Coming back to the familiar is nice, and I’ve been faffing around with Nginx in one form or another since 2011, so I have a reasonably solid understanding of how to crawl around in its configuration files. But far better than the fact that it’s all familiar is the fact that it’s not throwing any errors, and its PHP processes—provided by the venerable and bulletproof PHP-FPM and PHP 8.3—have been well-behaved and frugal with CPU resources. I still feel nervous in the mornings when Berger posts his weather update for the day, but much less so—and I anticipate my nervousness will continue to decrease as we get further from the problem.
But is it fixed?
Ah, now that’s the question that keeps me up at night. Is it fixed? How many angels can dance on the point of a needle? Who the hell knows? I never really found a singular root cause—as with so many problems in complex systems, the “root cause” seems likely to have been a confluence of a dozen unrelated issues that all hit at the same time. It feels like the core issue was a higher-than-normal load that exposed a fundamental weakness in my underlying OLS configuration, but the likely causal conditions (high load) have since more or less evaporated, making validation difficult.
On the other hand, I kind of went nuclear with the fix—I ripped out the entire hosting software stack and replaced it, so even if there are still some lurking issues with the Cloudflare configuration, we’ve at least radically changed the shape of the landscape on which the problem behavior expresses itself.
I guess I’ll just be over here, tailing log files and staring obsessively at CPU time in htop. Which… let’s be honest, it’s where I’d be anyway because I’m a sysadmin. It’s what we do.



