
AI chatbot deception paper suggests that some bots (and people) aren’t very persuasive.

In a preprint research paper titled “Does GPT-4 Pass the Turing Test?”, two researchers from UC San Diego pitted OpenAI’s GPT-4 AI language model against human participants, GPT-3.5, and ELIZA to see which could trick participants into thinking it was human with the greatest success. But along the way, the study, which has not been peer-reviewed, found that human participants correctly identified other humans in only 63 percent of the interactions—and that a 1960s computer program surpassed the AI model that powers the free version of ChatGPT.
FURTHER READING
People think white AI-generated faces are more real than actual photos, study says
Even with limitations and caveats, which we’ll cover below, the paper presents a thought-provoking comparison between AI model approaches and raises further questions about using the Turing test to evaluate AI model performance.
British mathematician and computer scientist Alan Turing first conceived the Turing test as “The Imitation Game” in 1950. Since then, it has become a famous but controversial benchmark for determining a machine’s ability to imitate human conversation. In modern versions of the test, a human judge typically talks to either another human or a chatbot without knowing which is which. If the judge cannot reliably tell the chatbot from the human a certain percentage of the time, the chatbot is said to have passed the test. The threshold for passing the test is subjective, so there has never been a broad consensus on what would constitute a passing success rate.
In the recent study, listed on arXiv at the end of October, UC San Diego researchers Cameron Jones (a PhD student in Cognitive Science) and Benjamin Bergen (a professor in the university’s Department of Cognitive Science) set up a website called turingtest.live, where they hosted a two-player implementation of the Turing test over the Internet with the goal of seeing how well GPT-4, when prompted different ways, could convince people it was human.Advertisement
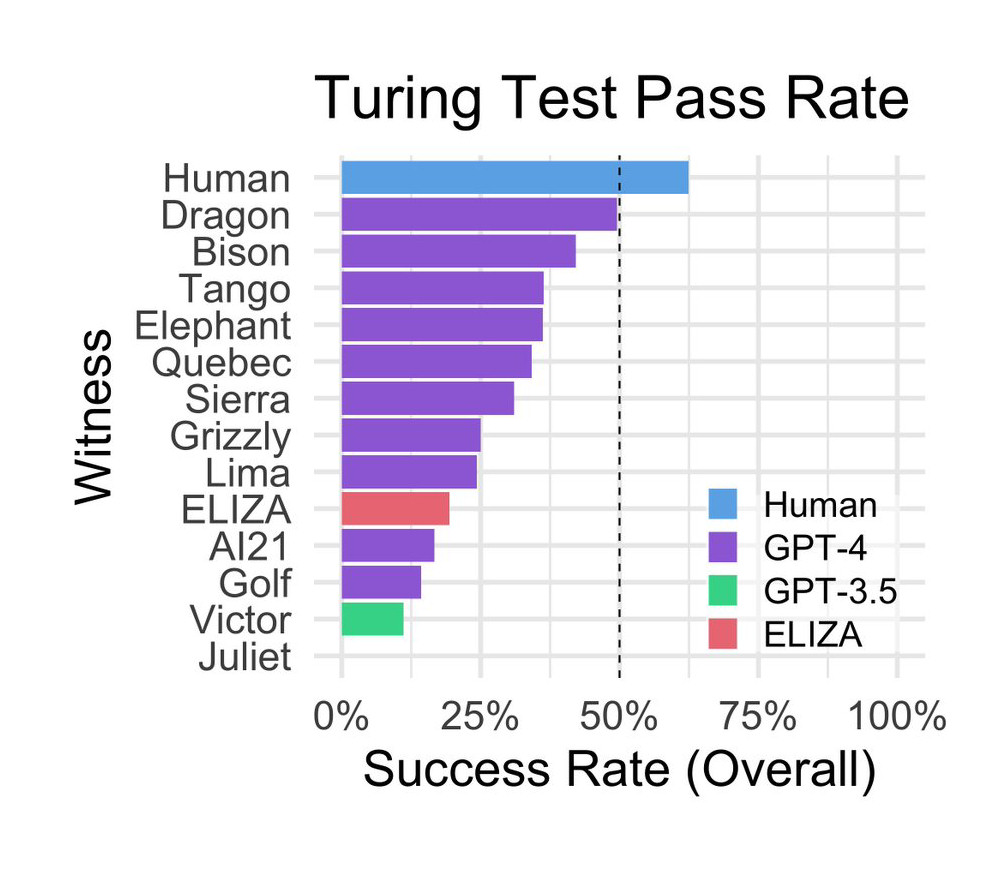
Through the site, human interrogators interacted with various “AI witnesses” representing either other humans or AI models that included the aforementioned GPT-4, GPT-3.5, and ELIZA, a rules-based conversational program from the 1960s. “The two participants in human matches were randomly assigned to the interrogator and witness roles,” write the researchers. “Witnesses were instructed to convince the interrogator that they were human. Players matched with AI models were always interrogators.”
ADVERTISING
The experiment involved 652 participants who completed a total of 1,810 sessions, of which 1,405 games were analyzed after excluding certain scenarios like repeated AI games (leading to the expectation of AI model interactions when other humans weren’t online) or personal acquaintance between participants and witnesses, who were sometimes sitting in the same room.
Surprisingly, ELIZA, developed in the mid-1960s by computer scientist Joseph Weizenbaum at MIT, scored relatively well during the study, achieving a success rate of 27 percent. GPT-3.5, depending on the prompt, scored a 14 percent success rate, below ELIZA. GPT-4 achieved a success rate of 41 percent, second only to actual humans.
GPT-3.5, the base model behind the free version of ChatGPT, has been conditioned by OpenAI specifically not to present itself as a human, which may partially account for its poor performance. In a post on X, Princeton computer science professor Arvind Narayanan wrote, “Important context about the ‘ChatGPT doesn’t pass the Turing test’ paper. As always, testing behavior doesn’t tell us about capability.” In a reply, he continued, “ChatGPT is fine-tuned to have a formal tone, not express opinions, etc, which makes it less humanlike. The authors tried to change this with the prompt, but it has limits. The best way to pretend to be a human chatting is to fine-tune on human chat logs.”Advertisement
Further, the authors speculate about the reasons for ELIZA’s relative success in the study:
During the sessions, the most common strategies used by interrogators included small talk and questioning about knowledge and current events. More successful strategies involved speaking in a non-English language, inquiring about time or current events, and directly accusing the witness of being an AI model.
The participants made their judgments based on the responses they received. Interestingly, the study found that participants based their decisions primarily on linguistic style and socio-emotional traits, rather than the perception of intelligence alone. Participants noted when responses were too formal or informal, or when responses lacked individuality or seemed generic. The study also showed that participants’ education and familiarity with large language models (LLMs) did not significantly predict their success in detecting AI.

The study’s authors acknowledge the study’s limitations, including potential sample bias by recruiting from social media and the lack of incentives for participants, which may have led to some people not fulfilling the desired role. They also say their results (especially the performance of ELIZA) may support common criticisms of the Turing test as an inaccurate way to measure machine intelligence. “Nevertheless,” they write, “we argue that the test has ongoing relevance as a framework to measure fluent social interaction and deception, and for understanding human strategies to adapt to these devices.”
GPT-4: fail. Humans: pass?
Ultimately, the study’s authors concluded that GPT-4 does not meet the success criteria of the Turing test, reaching neither a 50 percent success rate (greater than a 50/50 chance) nor surpassing the success rate of human participants. The researchers speculate that with the right prompt design, GPT-4 or similar models might eventually pass the Turing test. However, the challenge lies in crafting a prompt that mimics the subtlety of human conversation styles. And like GPT-3.5, GPT-4 has also been conditioned not to present itself as human. “It seems very likely that much more effective prompts exist, and therefore that our results underestimate GPT-4’s potential performance at the Turing Test,” the authors write.
FURTHER READING
OpenAI’s GPT-4 exhibits “human-level performance” on professional benchmarks
As for the humans who failed to convince other humans that they were real, that may reflect more on the nature and structure of the test and the expectations of the judges, rather than on any particular aspect of human intelligence. “Some human witnesses engaged in ‘trolling’ by pretending to be an AI,” write the authors. “Equally some interrogators cited this behavior in reasons for human verdicts. As a consequence, our results may underestimate human performance and overestimate AI performance.”
A previous Turing test study done by AI21 Labs from May found that humans correctly identified other humans about 73 percent of the time (failing to ID them in 27 percent of encounters). Informally, one might suspect that humans could succeed far more than 63 percent or 73 percent of the time. Whether we should actually expect higher success rates for humans or not is unclear, but the 27-37 percent failure gap may have implications in a future where people may deploy AI models to deceive others.
In an unrelated study from November (Miller, et al), researchers found that people thought AI-generated images of humans looked more real than actual humans. Given that knowledge, and allowing for technology improvements, if an AI model could surpass the 63-73 percent barrier, its communications could hypothetically appear more human than an actual human. The future is going to be an interesting place indeed.




{kind=link}